Чи можна довіряти h-індексу, розрахованому в Google Scholar?


- Деталі
- Створено: Вівторок, 29 серпня 2023, 11:37
- Перегляди: 2875
H-індекс – це не те, що кожному досліднику потрібно обчислювати щодня. Проте, знати, де ви знаходитесь в цьому плані, корисно з кількох причин.
По-перше, зростання показників h-індексу – це відзнака вашої роботи. Тому, нагородити себе за це особисте досягнення можна, зробивши якусь маленьку приємність, на кшталт випити смачне капучино. Але якщо серйозно, то h-індекс потрібен грантодавцям та відбірковим комісіям, що обирають кандидатів на міжнародне стажування, стипендію тощо. Враховуючи часто величезну кількість заявок, h-індекс розраховується для ранжування кандидатів.
H-індекс, автоматично розрахований у профілі автора Web of Science, Scopus і Google Scholar використовується для вимірювання наукової продуктивності на основі кількості публікацій і цитувань науковців. Однак, ще 10 років тому, результати дослідження (Farhadi et al., 2013) показали, що різниця в h-індексі між Scopus, Web of Science і Google Scholar очевидна і помітна. H-індекс Google Scholar є більшим у порівнянні з h-індексом у двох інших базах даних.
Отже, h-індекс у Google Scholar має тенденцію бути вищим, ніж у Scopus або WoS, через використання різних джерел даних. Для ілюстрації цієї відмінності часто застосовують h-індекс «рок-зірок» науки, таких як Стівена В. Хокінга: Web of Science — 85, Scopus — 78, Google Scholar — 132 (станом на серпень 2023 р.).
Можна говорити про деякі переваги h-індексу в Google Scholar, такі як включення «ранніх цитат» з препринтів (якщо препринт було розміщено в архіві, що індексується в Google Scholar), тоді як Web of Science та Scopus враховують лише цитати з опублікованих наукових статей, що пройшли процес рецензування.
Однак, оскільки підхід Google Scholar є повністю автоматичним і не підлягає жодному перегляду і «цензурі», ним також можна досить легко маніпулювати. І це не новина, адже в тому ж таки 2013 році дослідження (Delgado López-Cózar et al., 2013) виявило можливість маніпуляції з підрахунком цитувань. Для цього автори дослідження завантажили 6 документів на інституційний веб-домен, автором яких є фіктивний дослідник і посилалися на всі публікації членів дослідницької групи EC3 в Університеті Гранади. Виявлення Google Scholar цих статей спричинило сплеск кількості цитувань, включених до профілів Google Scholar Citations авторів.
Отож, маніпуляціями можуть бути, наприклад, завантаження фальшивих наукових статей (навіть штучний інтелект може генерувати шматки текстів; проте варто зауважити, що хоча ChatGpt може допомогти у створенні вмісту для наукової статті, він не може написати статтю повністю сам по собі, — людський досвід, критичне мислення та аналіз, на щастя, все ще важливі в процесі написання), які містять непідтверджені цитати автора, що додають цьому автору певної кількості цитувань. Або маніпуляцією може бути додавання статей до профілю Google Scholar, автором яких навіть не є відповідна особа. Сьогодні у соціальних мережах все частіше з'являється реклама з недоброчесними послугами від хижацьких агенцій, що пропонують збільшити h-індекс в Google Scholar штучно. Такі приклади академічної недоброчесності можуть вплинути на майбутній розвиток таких продуктів, як Google Scholar, особливо якщо Google Scholar продовжить свою політику непрозорості.
Якщо ж ви не впевнені у результатах автоматичного обчислення h-індексу, можна дуже легко обчислити його самостійно. Для цього потрібно знати лише кількість своїх публікацій та кількість цитувань кожної з них. Перевірити кількість цитувань можна у безкоштовних реферативних базах даних, що індексують матеріали на основі DOI, наприклад Dimensions, Scilit або The Lens.
Отож, як обчислити свій h-індекс:
Крок 1. Перелічіть усі опубліковані статті у вигляді списку чи таблиці.
Крок 2: Для кожної статті знайдіть і запишіть кількість цитувань.
Крок 3: Розташуйте в порядку зростання ваші статті за кількістю цитувань (1, 2, 3, 4, 5…), де 1 має найбільше цитувань, і т.д.
Крок 4: h-індекс тепер можна визначити, знайшовши запис, у якого ранг у списку перевищує кількість цитувань. Наприклад:
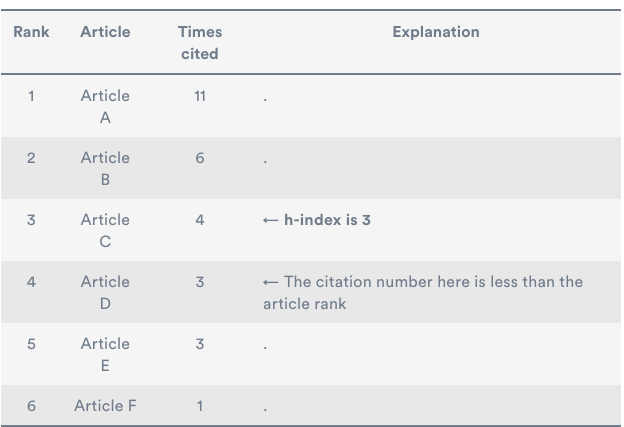
Якщо в результаті такого «ручного» обчислення виявилось, що у вас є цитовані роботи, не враховані в розрахунку h-індекс у Web of Science, Scopus і Google Scholar, напр. оскільки вони містяться в матеріалах конференції, не проіндексованої в цих ресурсах, то ви можете вказати це у своїй грантовій заявці. Це може додатково підвищити ваш рейтинг.
Можна зробити висновок, що має значення, які інструменти цитування використовуються для обчислення h-індексу. Тому університети та відбіркові комітети мають уточнювати, який саме інструмент використовувати для обчислення h-індексу дослідника чи викладача. Загалом, коли ми маємо намір повідомити свій h-індекс, нам потрібно врахувати та згадати джерело цього показника (Web of Science, Scopus чи Google Scholar). Також хочемо нагадати, що практики академічної недоброчесності (такі як плагіат, публікація в хижацькому журналі, який не здійснює належної процедури рецензування, подача неправдивих показників імпакт-фактору журналу або h-індексу науковця, не кажучи вже про геть абсурдну можливість «накручувати» h-індекс) є негідною поведінкою для науковця. Все таємне рано чи пізно все-таки стає явним.
А в Google Scholar є можливості для вдосконалення, проте h-індекс, розрахований на його основі, є все ще є актуальною безкоштовною альтернативою базам даних на основі підписки.
Література:
1. Delgado López-Cózar, E., Robinson-García, N., & Torres-Salinas, D. (2013). The Google scholar experiment: How to index false papers and manipulate bibliometric indicators. Journal of the Association for Information Science and Technology, 65(3), 446–454. https://doi.org/10.1002/asi.23056
2. Farhadi, H., Salehi, H., Yunus, M. M., Aghaei Chadegani, A., Farhadi, M., Fooladi, M., & Ale Ebrahim, N. (2013, March 27). Does it matter which citation tool is used to compare the h-index of a group of highly cited researchers? Australian Journal of Basic and Applied Sciences. http://eprints.rclis.org/19367/





